Introduction
The role of diversity analysis extends beyond the conservation and management of genetic resources (Salgotra and Chauhan, 2023); it is also critical for the continuity and success of plant breeding programs, which depend on access to a diverse population (Ebert et al., 2023). Molecular markers are widely used tools in diversity assessment, with simple sequence repeats (SSRs) or microsatellites and SNP markers being particularly valuable due to their ability to detect high genetic variability and their abundance in the genome (Zhu et al., 2016). Although SSRs are cost-effective, highly polymorphic markers, they are gradually replaced by SNP markers. However, breeding institutes with limited funds often prefer SSR markers due to their high polymorphism, computational simplicity, and accessibility to many molecular laboratories (Choudhury et al., 2023). The robustness of both marker systems has been demonstrated in crops such as rice (Singh et al., 2013), juniper (García et al., 2018), perennial ryegrass (Liu et al., 2018), and melon (Zhang et al., 2023). Each marker type has shown strengths in various diversity analysis aspects, such as SNPs for assessing geographic isolation and SSRs for parental assignment. Combining these marker technologies is useful for variety verification and DNA fingerprinting of large crop families like melon (Zhang et al., 2023).
Currently, there are eight Musa genome sequences available. Due to the ploidy level of Musa spp., Martin et al. (2016) used the double haploid Pahang to improve the assembly of the M. acuminata genome, which was chosen because it is one of the progenitors of domesticated Cavendish bananas. M. acuminata became the first Musa species and the first monocot outside the Poales order to have a draft genome sequence, establishing it as the model species for sequencing other Musa spp., such as M. itenerans (Wu et al., 2016), M. balbisiana Colla (Niu et al., 2018), and M. banksii (Liu et al., 2021). Studies on genomes of wild relatives like M. itenerans have provided insights into whole-genome duplication events that contributed to species divergence (Wu et al., 2016). Disease resistance elements identified in the genome sequences of these species also suggest the potential for gene introgression from wild relatives with both resistance and desirable agronomic traits, facilitating the development of Musa varieties that are well-adapted to multiple environments.
Abaca (Musa textilis Nee), an endemic fiber species from the Philippines, is clonally propagated and perennial. Approximately 84% of abaca fiber production is attributed to the Philippines (Halos, 2008). This natural fiber crop occupies unique market niches, such as paper bill manufacturing and the natural textile industry, highlighting the need to improve this high-value commodity to meet local and international demands. While vegetative propagation ensures that true-to-type traits are preserved across generations, it also results in a narrow genetic base and genomic erosion due to the lack of recombination (Liu et al., 2023). The distribution of this crop, along with its physical similarity to other Musa species, has led to misidentification and mismanagement within the abaca gene bank. Many abaca varieties have been given different names despite identical accessions (Halos, 2008).
The utility of molecular markers in breeding programs depends on marker quantity and quality (Kaldate et al., 2017). Most SSR markers used for abaca are banana-based or cross-transferred from non-Musa species. Of these, six banana-based markers have shown polymorphism within the abaca germplasm collection (Boguero et al., 2016; Yllano et al., 2020). Genome-wide SSR markers derived from publicly available whole genome assemblies have enhanced diversity analysis, linkage mapping, and marker – trait associations in several crops, including banana (Biswas et al., 2020), walnut (Itoo et al., 2023), grain amaranth (Vats et al., 2023), wheat (Fandade et al., 2023), and citrus (Singh et al., 2023). For instance, molecular markers developed from the genome assembly of flax have differentiated fiber and linseed types (Pan et al., 2020). Multiple studies have investigated critical components of abaca genomics and transcriptomics to elucidate the genetic composition of the crop. These include SSRs linked to economically significant diseases and fiber quality (Lalusin, 2010; Damo, 2011; Dizon et al., 2012; Pabro, 2012; Palao, 2018; Yllano et al., 2020), filtered genome analysis (Vilela et al., 2015), and transcriptome studies (Muncada, 2018; Reamillo, 2018). The release of the 616 Mbp abaca var. Abuab de novo whole genome assembly offers a valuable resource of molecular markers (Galvez et al., 2021). Genome-wide SSRs from the abaca genome assembly provide an efficient marker system to analyze genetic relatedness within the abaca gene bank, determine population structure, and facilitate varietal identification.
In this study, we developed, identified, and characterized 50 microsatellite markers to comprehensively assess the genetic diversity and variety identity of the UPLB (University of the Philippines Los Baños) abaca collection from 10 regions in the country (Supplementary Table 1). Using multiple genetic diversity software programs, we assessed the genetic relatedness of abaca and evaluated the markers’ efficiency in detecting other Musa species with physical similarities to abaca. Finally, we analyzed the collinearity of the results from these new markers across different software to evaluate their consistency in discrimination power.
Materials and methods
Genome SSR marker design
Before using the GMATA (Genome-wide Microsatellite Analyzing Tool Package; Wang and Wang, 2016) program to generate genome-wide SSR markers, specific preparatory steps were undertaken. In the phylogenetic tree established by Galvez et al. (2021), abaca (M. textilis Nee) was found to be more closely related to M. balbisiana Colla than to M. acuminata. Therefore, the M. balbisiana genome was used as the reference to create a reference-based chromosome assembly for M. textilis Nee.
The Chromosomer software (Tamazian et al., 2016) was employed to build a straightforward chromosome assembly based on the pairwise alignment of scaffolds and contigs to the reference genome. Fragments were aligned twice — once in the forward direction and once in reverse — against the reference. The M. textilis Nee genome, available at https://datadryad.org/stash/share/Yk6Ls1qw7WQts4zl03iPEchuiw6kMKBJBy6Oa1-JN00, was obtained from the Data Dryad repository (Galvez et al., 2021). The M. balbisiana Colla chromosome assembly was obtained from https://www.ncbi.nlm.nih.gov/datasets/genome/GCA_004837865.1/ (Wang et al., 2019). Only the mapped fragments of the M. textilis Nee genome were processed through the GMATA program.
To generate primer pairs, the mapped M. textilis Nee fragments were analyzed using GMATA under default settings: dinucleotide (2) to hexanucleotide (6) motif repeats, a minimum amplicon size of 120 bp, an optimal annealing temperature of 60°C, a minimum GC content of 40%, and a primer length of 18–25 bp. The SSR selection process described by Bhattarai et al. (2021) for spinach g-SSRs was then applied to filter the microsatellite markers. The following criteria were used to exclude markers from the study: 1) motifs without designed flanking regions, 2) markers with an AT/TA motif, and 3) loci within 100 bp of each other. Finally, markers showing polymorphism, as determined by the GMATA e-mapping program, were retained as the final set of SSR markers for this study.
Plant materials and polymerase chain reaction
A total of 99 Musa textilis accessions, collected from 10 administrative regions of the Philippines, were used in this study (Supplementary Table 1). Six accessions from this collection exhibited morphological similarities to bananas. To confirm this observation, two dendrograms were generated (Fig. 3 and Fig. 10).
DNA was isolated using the Doyle and Doyle (1990) CTAB DNA extraction protocol, as modified by Sandoval et al. (2011). The PCR conditions were adapted from the protocols described by Boguero et al. (2016) and Yllano et al. (2020). Each 10 μl PCR reaction consisted of 1× PCR buffer, 2 mM MgCl2, 0.2 mM dNTPs, primers (forward and reverse), and 0.05 U/μl Taq polymerase cocktail. The PCR cycling conditions were as follows: initial denaturation at 94°C for 4 min; 35 cycles of denaturation at 94°C for 30 s, annealing at 58–59.9°C for 30 s, and extension at 72°C for 45 s; followed by a final extension at 72°C for 10 min. The amplified bands were visualized on a 6% polyacrylamide gel stained with GelRed and analyzed using the GenoSens photodocumentation system. Polymorphic bands were scored with the GelAnalyzer v.23.1 software (Lazar and Lazar, 2023).
Data analysis
To comprehensively assess the genetic relatedness of the abaca collection, allele frequency, genetic distance, principal coordinate analysis (PCoA), and analysis of molecular variance (AMOVA) were determined using GenAIEx v.6.5 (Genetic Analysis in Excel) software (Peakall and Smouse, 2012). Following the Hardy–Weinberg Equilibrium (HWE) framework in GenAIEx, the expected heterozygosity was calculated using the formula:
where H – diversity index,
The Jaccard index was computed in the Dissimilarity Analysis Representation for Windows (DARwin) software ver. 6.0.21 (Perrier and Jacquemoud-Collet, 2006) using the formula:
where dij is the distance index between i and j ; a is the number of variables where xi – present and xj – present; b is the number of variables where xi – present and xj – absent; c is the number of variables where xi – absent and xj– present.
The unweighted neighbor-joining tree was constructed using DARwin software v.6.0.021, with 1,000 bootstrap repetitions. Population assignment for each accession was computed using STRUCTURE software v.2.3.4 (Pritchard et al., 2000). In this admixture model, a total of ten replications for each K value were performed, with each K run over a burn-in period of 20,000 iterations and 50,000 Monte Carlo Markov Chain (MCMC) replicates.
The optimal K-means cluster was determined using the R package Pophelper v.2.3.1 (Francis, 2017; https://github.com/royfrancis/pophelper). The degree of population differentiation among the four subpopulations was assessed using Hierfstat. To test the collinearity between the two clustering methods, a Venn diagram was generated using the Venny 2.1 analysis program (https://bioinfogp.cnb.csic.es/tools/venny/), developed by Oliveros (2007).
Results
Genome-wide SSR marker analysis
Since the only available genomic data for abaca consisted of scaffolds, the Chromosomer software was utilized to ensure the SSR markers were developed within the aligned scaffolds for greater accuracy. Chromosomer generated a chromosome assembly based on the alignment of the M. textilis Nee genome (query) with the M. balbisiana Colla genome (reference).
The Chromosomer software mapped the Abuab genome (Galvez et al., 2021) to the 11 chromosomes of M. balbisiana Colla, aligning 11,720 fragments or 221.5 Mbp of the 473 Mbp (-46.8%) M. balbisiana Colla chromosome assembly. This mapping produced 7,615 unlocalized fragments and 26,738 unplaced scaffolds. Only the mapped fragments were used to avoid developing markers from unlocalized or unplaced regions. A total of 50 genome-wide SSR markers were designed and applied to assess the diversity of the abaca germplasm collection. Among these, 28 polymorphic primers were identified and used for all subsequent analyses.
Since six abaca accessions exhibited morphological similarities with bananas, two clusters were generated to highlight the genetic and morphological differences between abaca and banana-like accessions. This was necessary, as natural hybrids such as Canton and Minay exist (Halos, 2008). The morphological similarities between abaca cultivars have historically resulted in misidentification, with many accessions sharing identical or similar names due to traditional propagation via suckers, which farmers often label with the same identification.
Figure 1 shows that the most abundant motifs in the Abuab genome assembly were AT and TA, representing 22.5 and 21.2%, respectively. However, these motifs were excluded due to scoring difficulties and reproducibility issues (Bhattarai et al., 2021). While the highest number of SSRs was found in > scaffold7752, none of the designed markers from this scaffold were polymorphic and therefore were not included in the study.
Fig. 1
(A) SSR motif distribution and (B) frequencies of SSR markers distributed on the scaffolds of the molecular markers developed from the aligned Abuab genome (Musa textilis Nee) using the GMATA program
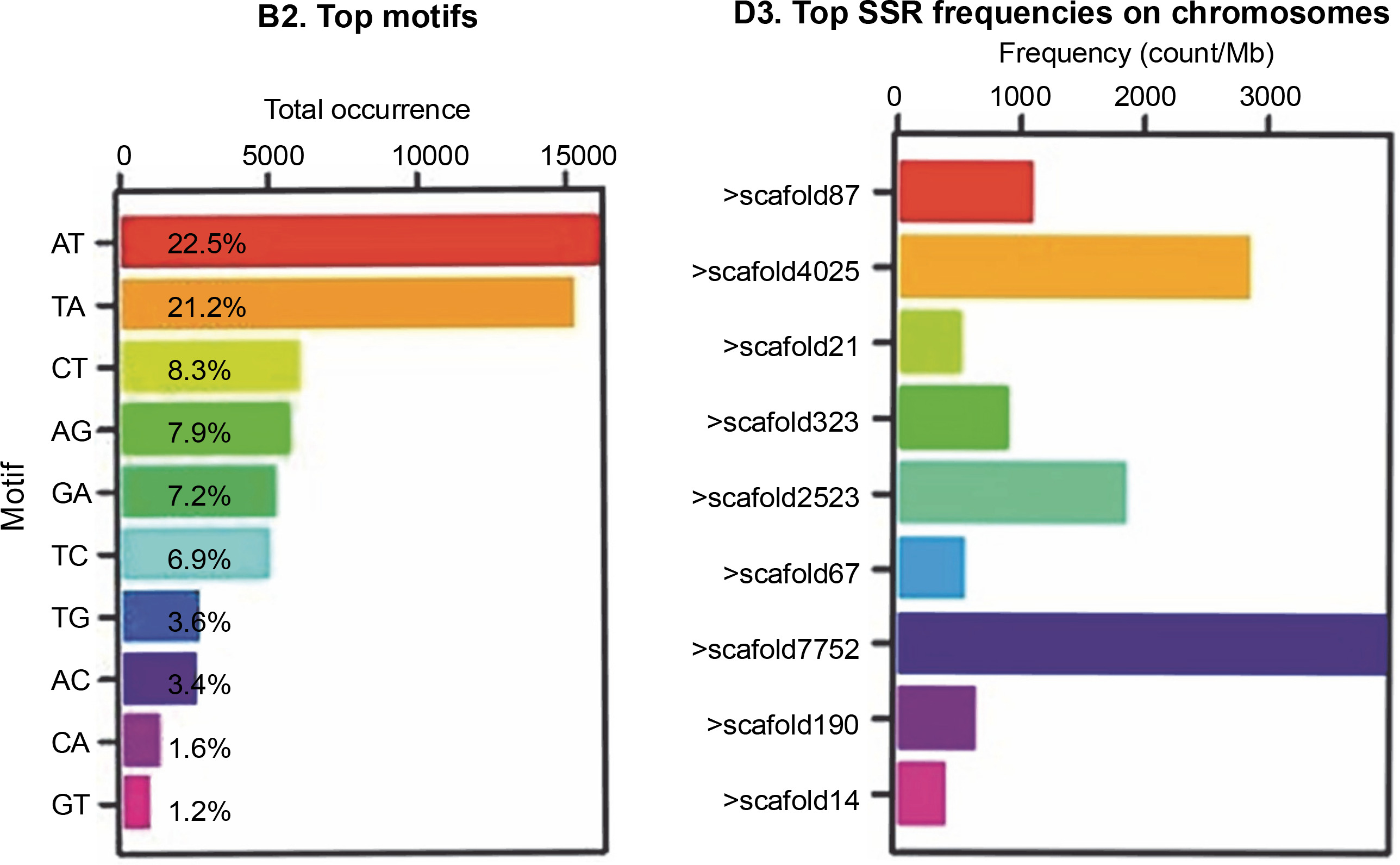
Table 1 details the 28 polymorphic SSR markers developed using the GMATA program, including motifs, fragment locations, corresponding M. balbisiana Colla chromosomes, annealing temperatures, expected product sizes, and PIC values. Chromosomes 2 and 3 were not represented. PIC values ranged from 0.49 to 0.91, with an average of 0.78, indicating that this marker set is highly informative and suitable for genetic analysis and variety fingerprinting.
Table 1
The profile of the polymorphic genome wide SSR markers used in assessing the diversity of the abaca (Musa textilis Nee) germplasm collection
The average heterozygosity obtained from the 99 samples was 0.428 based on the HWE analysis of GENAIEx v.6.5 software, suggesting moderate heterogeneity. The population used in this study served as a germplasm collection with representative accessions from the ten administrative regions of the Philippines. Modified PCR protocols previously used in abaca molecular studies (Boguero et al., 2016; Yllano et al., 2020) were applied to the newly developed markers, resulting in bands ranging from 187 to 236 per population, with band frequencies $5% ranging from 173 to 193 (Fig. 2). Unique bands in each of the four subpopulations ranged from 16 to 48, while shared bands across # 50% of populations ranged from 33 to 50 alleles (Table 2). These unique bands may serve as distinct markers for specific abaca populations or accessions in future studies.
Table 2
Allelic distribution and band frequencies across the four abaca (Musa textilis Nee) subpopulations
| Population | Pop1 | Pop2 | Pop3 | Pop4 |
|---|---|---|---|---|
| No. bands | 236 | 230 | 187 | 246 |
| No. bands Freq. ≥ 5% | 173 | 179 | 187 | 194 |
| No. private bands | 48 | 32 | 16 | 42 |
| No. LComm bands (≤ 50%) | 44 | 46 | 33 | 50 |
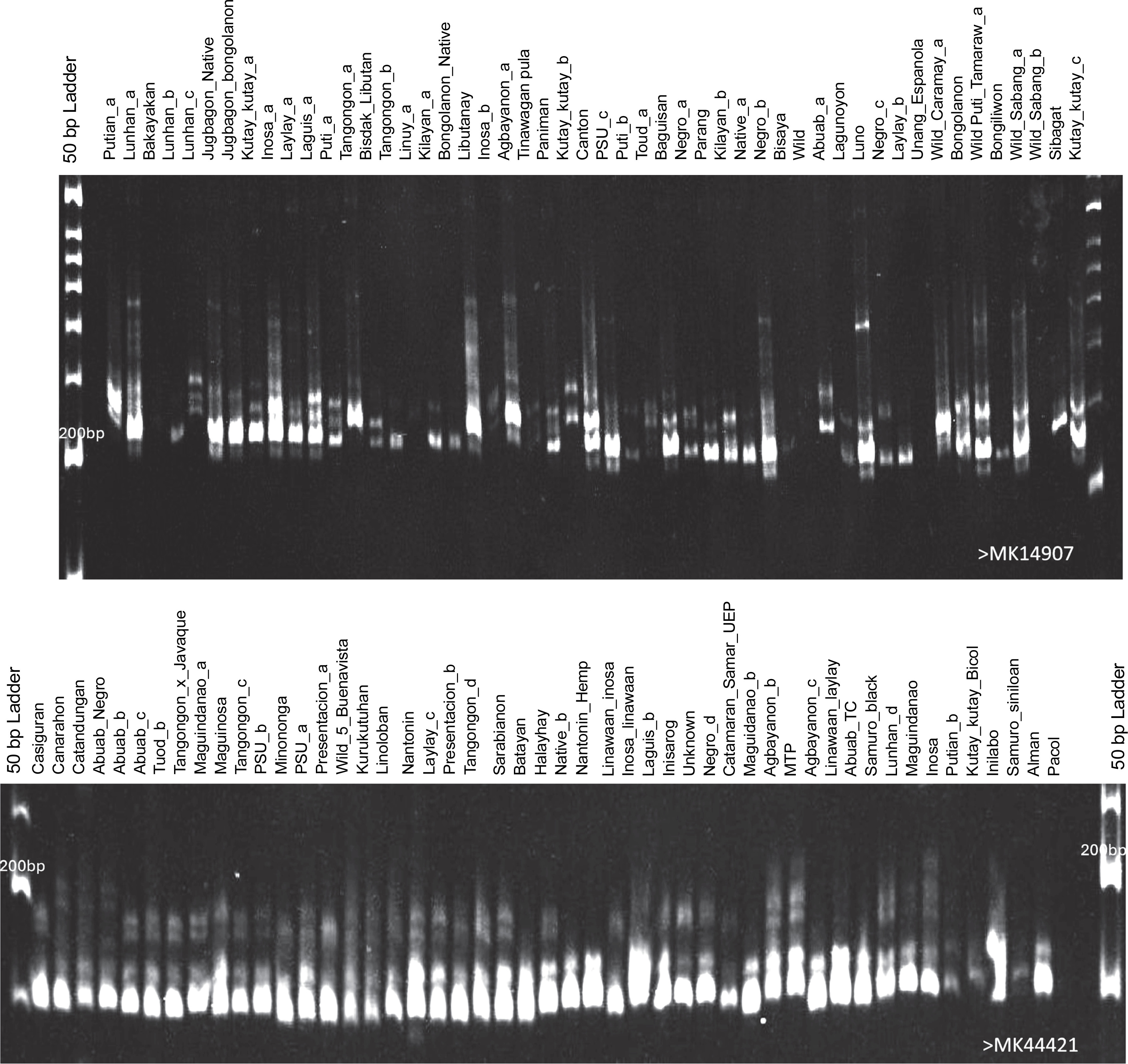
Fig. 2
Representative 6% polyacrylamide gels showing the generated polymorphic bands of the abaca (Musa textilis Nee) accessions using markers MK14907 and MK44421
The SSR markers developed from the M. textilis var. Abuab genome improved the specificity and accuracy of abaca genetic characterization. This research advances previous molecular studies of abaca, which relied on markers derived from the genomes of other Musa species or distant plant genera.
In this study, the SSR markers proved robust for diversity assessment, effectively delineating abaca accessions at the genetic level and confirming moderate diversity within the population. The SSR marker system offers rapid, accessible results and does not require a skilled bioinformatician or advanced computational resources, making it feasible for use in established molecular laboratories. The SNP marker system, on the other hand, is largely outsourced in the Philippines, and only a few agencies are capable of sequencing (i.e., Philippine Genome Centers); therefore, the SSR marker system is a good choice for studies dealing with genetic diversity.
Cluster analysis of the 93 abaca (Musa textilis Nee) accessions
Two neighbor-joining trees were generated in this study. The first tree included only 93 abaca accessions (Fig. 3), while the second incorporated six accessions with morphological similarities to bananas to illustrate the genetic differences between these accessions and true abaca. The radial tree grouped the 93 abaca accessions into four clusters using an average Jaccard similarity index of 0.69, indicating moderate dissimilarity among accessions.
Fig. 3
Diversity analysis of the 93 abaca accessions (Musa textilis Nee) using 28 polymorphic genome-wide microsatellite markers generated through the DARwin v.6.0 software
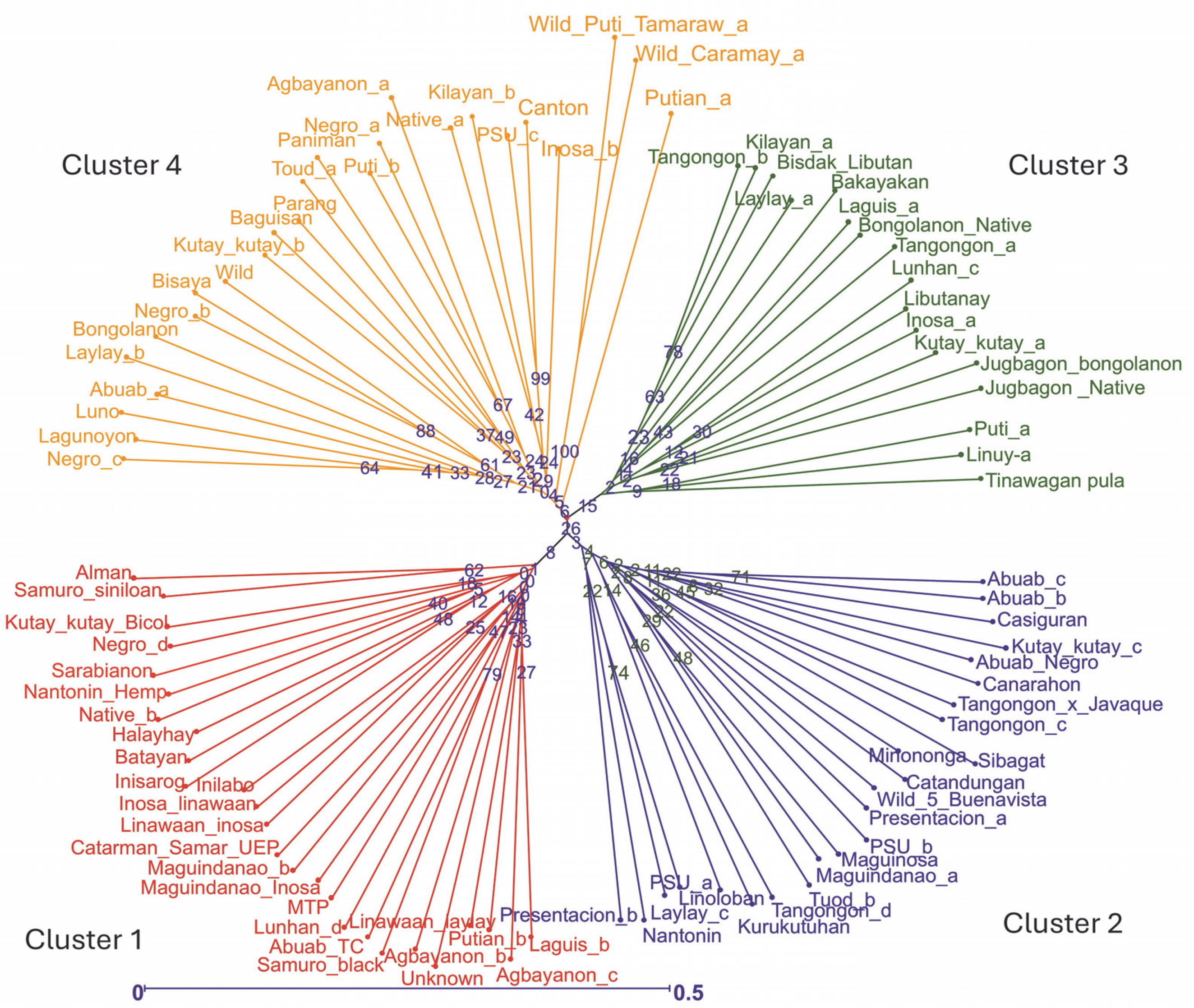
Cluster 1 consisted of 26 abaca accessions from nine administrative regions of the Philippines. Region 5 had the highest representation at 26.9%, followed by Regions 6, 8, and 13, each contributing approximately 15%. Notably, Region 5 is among the largest producers of abaca. Accessions Linawaan_inosa and Inosa_linawaan are grouped closely within this cluster. These accessions also showed high percent similarity among the subpopulations generated by population structure. The only Negro accession placed in cluster 1 was Negro_d, indicating its genetic difference from the other Negro accessions. This observation was confirmed in the population structure analysis. Both Samuro_black and Samuro_siniloan, which came from different areas (Region V and Region IV-A, respectively), but bear the Samuro name were found in this cluster. The Samuro cultivar is typically found in Region V (Halos, 2008). This region lies around 300km away from Laguna (Region IV-A) where Samuro_siniloan was found. Despite coming from the same region, only Agbayanon_a was separated from other accessions bearing the same label, suggesting that this cultivar might have originated from other regions.
Cluster 2 was composed of 24 abaca accessions that were collected from six regions. The Bicol region has the highest share in this group at 39%, followed by regions 4 and 12, which contributed 26 and 17%, respectively. The most notable result in this cluster was the Abuab cultivars. The Abuab_b, Abuab_c, and Abuab_negro collected from Region 5 were grouped in Cluster 2, while Abuab_a acquired from Region 3 was observed in Cluster 4, where no other Abuab were found. Given that Abuab is typically found in the Bicol Region (Department of Agriculture, 2018), Abuab_a from Region 3 is probably a misidentified abaca accession. In addition, a large portion of the percent shared alleles (-95%) shown in Figure 5 of Abuab_a came only from cluster 4, suggesting it is a different accession from the rest of the Abuab cultivar.
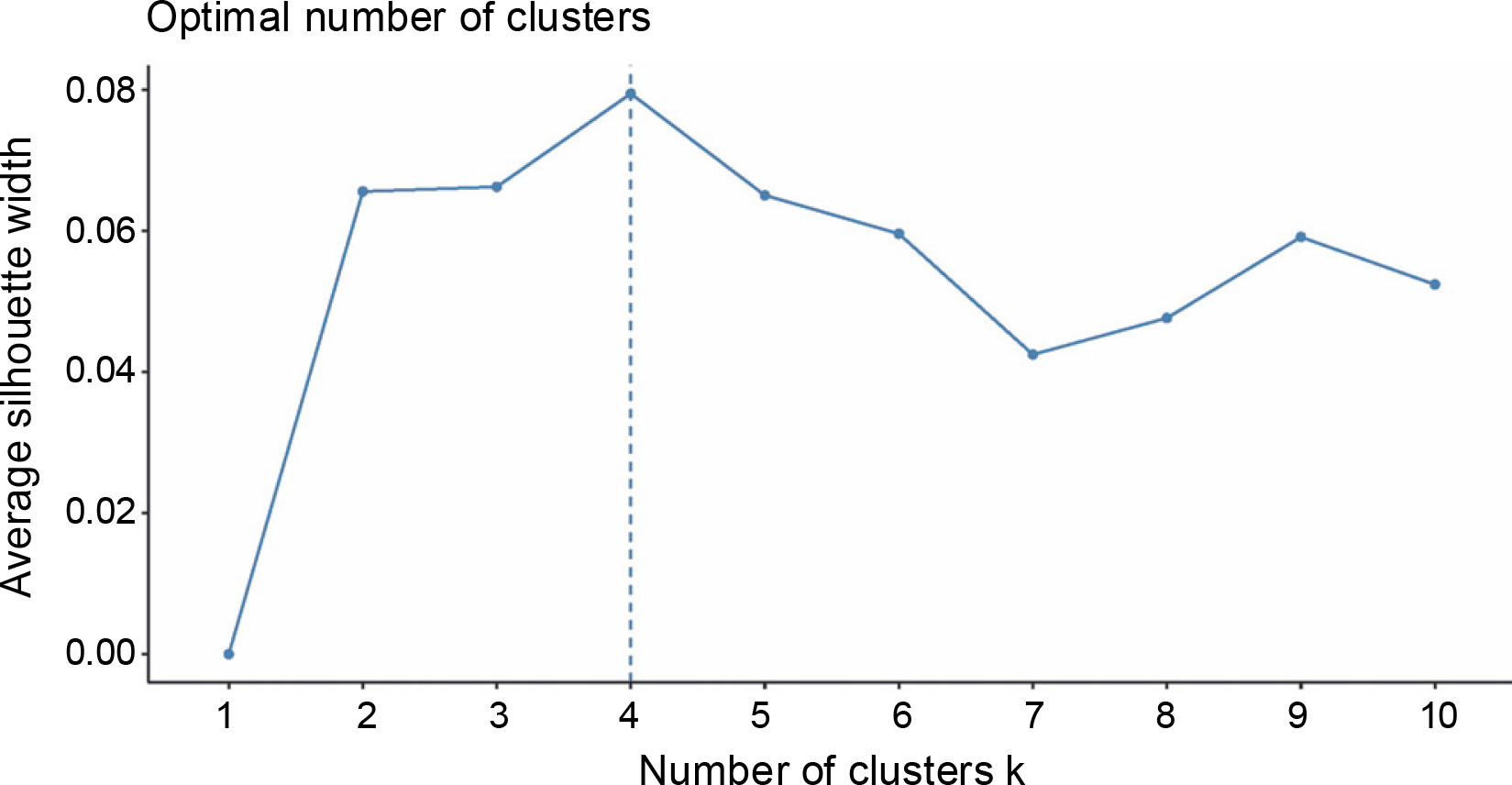
A total of 20 samples were grouped in cluster 3. Around 45% of this population originated from Region 9, while 30% came from Region 3, and 10% were from Region 8. This is the only cluster that deviated from the rest of the grouping since its members largely came from a region in Mindanao, indicating their genetic dissimilarity with the abaca accessions found in other regions. Three Lunhan and two Tangongon accessions are found here. The accessions with Jugbagon names are also placed in this cluster. This suggests that the cultivars found in this cluster are associated with one another and originated in region 9. Cluster 4 was composed of 23 abaca samples. The majority of accessions here are from Region 5 (39%), while Regions 6 and 3 shared 17% of the total number of abaca members in this group. Three Negro accessions, Abuab_a, and Inosa_b are the most notable members of this cluster, for they were separated from other abaca that share the same names. Clusters 1, 2, and 4 were dominated by abaca accessions from the Bicol region, and only cluster 3 was composed mostly of accessions from region 9 (-45%). Many of the accessions that have large similarities in their alleles were grouped in the same clusters, except for Kutay-Kutay, Laylay, and Puti which have a representative for every cluster. This cluster analysis is supported by the results of the NbClust package (Fig. 4), which suggests that the optimal k was four clusters. A 90% cophenetic correlation also proved the outcome of this study. It indicates a high goodness of fit of the generated unweighted neighbor-joining tree. The regions where the accessions were collected are important in this study due to abaca cultivars’ physical similarity with one another and their mode of distribution (using suckers), which can lead to misidentification or mislabeling of the cultivars.
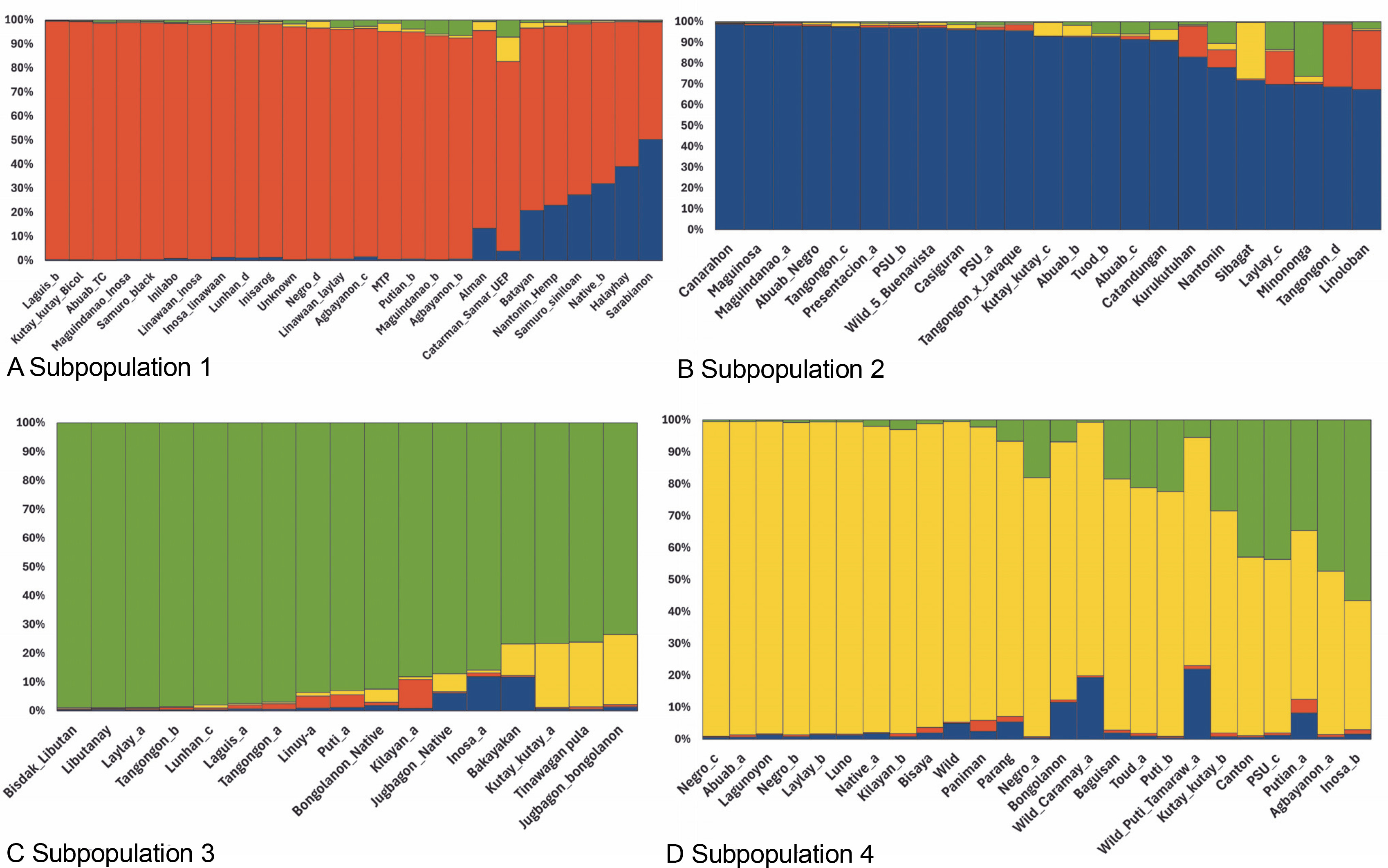
Bayesian model-based population structure
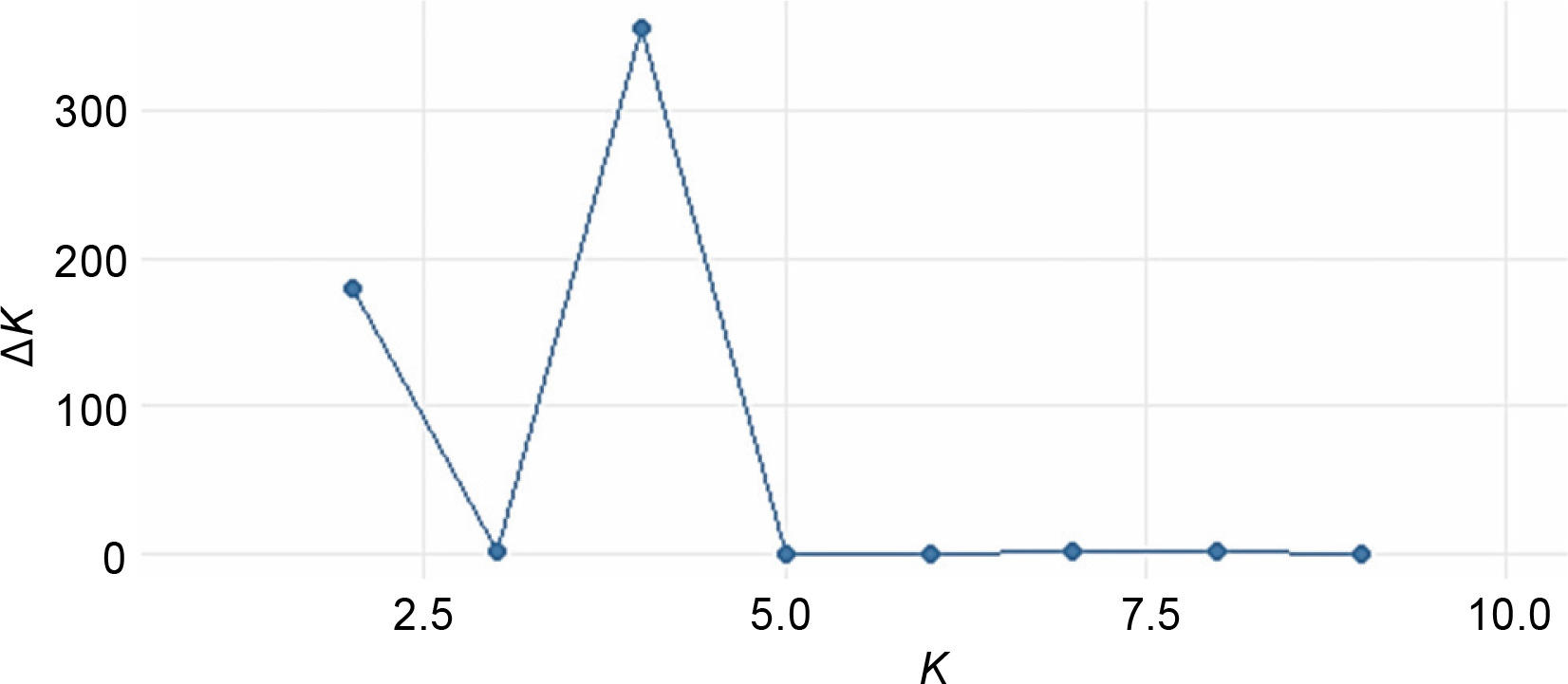
The STRUCTURE software v.2.3.4 was used to further define the observed clustering of the 93 abaca accessions and confirm the results of the neighborjoining tree. The percentage of alleles shared between clusters is shown in Figure 5. The population structure corroborated with the cluster analysis generated by the DARwin software but with a few exceptions: Inosa_b, Lunhan_a, Putian_a, and Sarabianon regrouped into the adjacent subpopulation in this analysis. Subpopulation 1 (Fig. 5A) includes 25 abaca samples, where the inferred shared alleles ranged from 59.9 (Halayhay) to 99.1% (Kutay_kutay_Bicol). The large portion of the allelic distribution of Kutay_kutay_Bicol in subpopulation 1 indicates its genetic difference and uniqueness from other Kutay_kutay cultivars placed in other groups. Lina-waan_inosa and Inosa_Linawaan only differ by 0.4% of shared alleles, suggesting that they are the same accessions bearing interchanged names. In addition, these samples were also collected in the same region (Region 8). This also confirms the cultivars’ close association with the neighbor-joining tree (Fig. 3). Samuro_black and Samuro_siniloan share 98.6 and 70.8% of alleles from subpopulation 1, respectively, compared to other clusters, indicating they are related but not of the same accession. The samples Agbayanon_b and Agbayanon_c are both members of subpopulation 1 based on the -90% shared alleles but have varying percent alleles coming from other clusters, suggesting they are highly associated but not the same cultivars. Subpopulation 2 (Fig. 5B) is composed of 25 individuals. Sarabianon, which was placed in cluster 1 by the UNJ tree, was moved to subpopulation 2. This is because the alleles it shares with subpopulation 1 are almost at a 50/50 ratio: 48.6 (subpopulation 1) and 50.7% (subpopulation 2). Darwin may have placed it in cluster 1, ignoring the 2.1% difference in shared alleles. Using different diversity analysis programs is important to generate robust results in SSR markers. Both Presentation, a and b, are found in this subpopulation but bear different inferred ancestry or shared alleles (97.6 and 43.9%), indicating an association and molecular difference of the cultivars. All Abuab and PSU accessions here also shared more than 90% of subpopulation 2 but were a mix of different shared alleles; hence, they are highly associated but not the same accessions. Tangongon_c and the hybrid Tangongon x Javaque were more similar in shared alleles (-90%) than Tangongon_d (71%), indicating that the hybrid is more genetically similar to Tangongon_c than the Tangongon_d cultivar. Subpopulation 3 (Fig. 5C) is composed of 18 abaca accessions. Inosa_a and Inosa_b were collected from regions 13 and 8 and have different shared percent allele distribution in the subpopulation (85.9 and 58.5%, respectively), indicating low genetic similarity. In addition, Inosa_b, like Sarabianon, was also placed in the adjacent group (cluster 4) in the NJ tree. The Jugbagon_native (93.8%) and the hybrid Jugbagon_bongolanon (78%) are related according to their percent shared in subpopulation 3 but demonstrate genetic differences, the alleles shared by the Bongolanon parent with the hybrid is considered a factor for the allelic differences. Only Lunhan_a, which was previously grouped in a cluster of the NJ tree, got separated from Lunhan b and c cultivars and was placed in the adjacent subpopulation 4. In subpopulation 4 (Fig. 5D), the shared allelic percentage ranged from 47.3 (Putian_a) to 99% (Negro_c). Similar to the UNJ tree generated by DARwin, the three Negro accessions were grouped in this subpopulation. They possess varying percent alleles: Negro_a (80.2%), Negro_b (98%), and Negro_c (99%). This suggests that Negro_d, placed in subpopulation 1, possesses a different allelic distribution than the other Negro accessions. The measure of subpopulation differentiation obtained for the structure analysis was α = 0.0735 and average Fstp = 0.0815, both suggesting moderate genetic diversity. According to the Evanno method implemented in the Pophelper package, the optimum K clustering in this collection was four (Fig. 6), similar to the result obtained from the NbClust package (Fig. 4) generated for the UNJ tree.
Fig. 5
Four subpopulations generated by the STRUCTURE software v 2.3.4 for abaca (Musa textilis Nee) are based on the results of the 28 polymorphic genomic SSR markers; the red group (A – subpopulation 1), blue group (B – subpopulation 2), and yellow group (D – subpopulation 4) were composed mostly of abaca accessions from Region 5 while the majority of the green group © – subpopulation 3) were from Region 9
AMOVA and PCOA of the four abaca populations
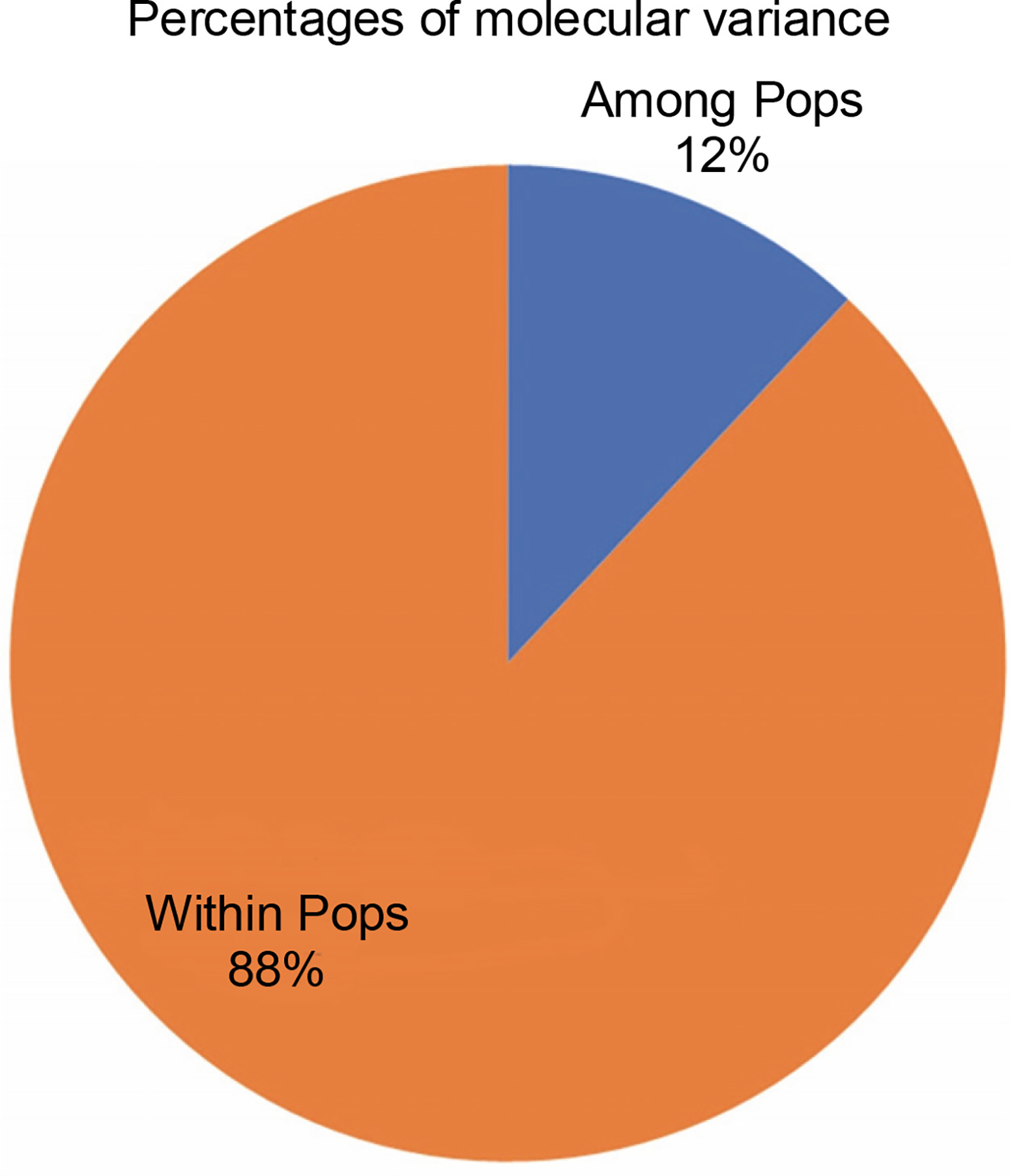
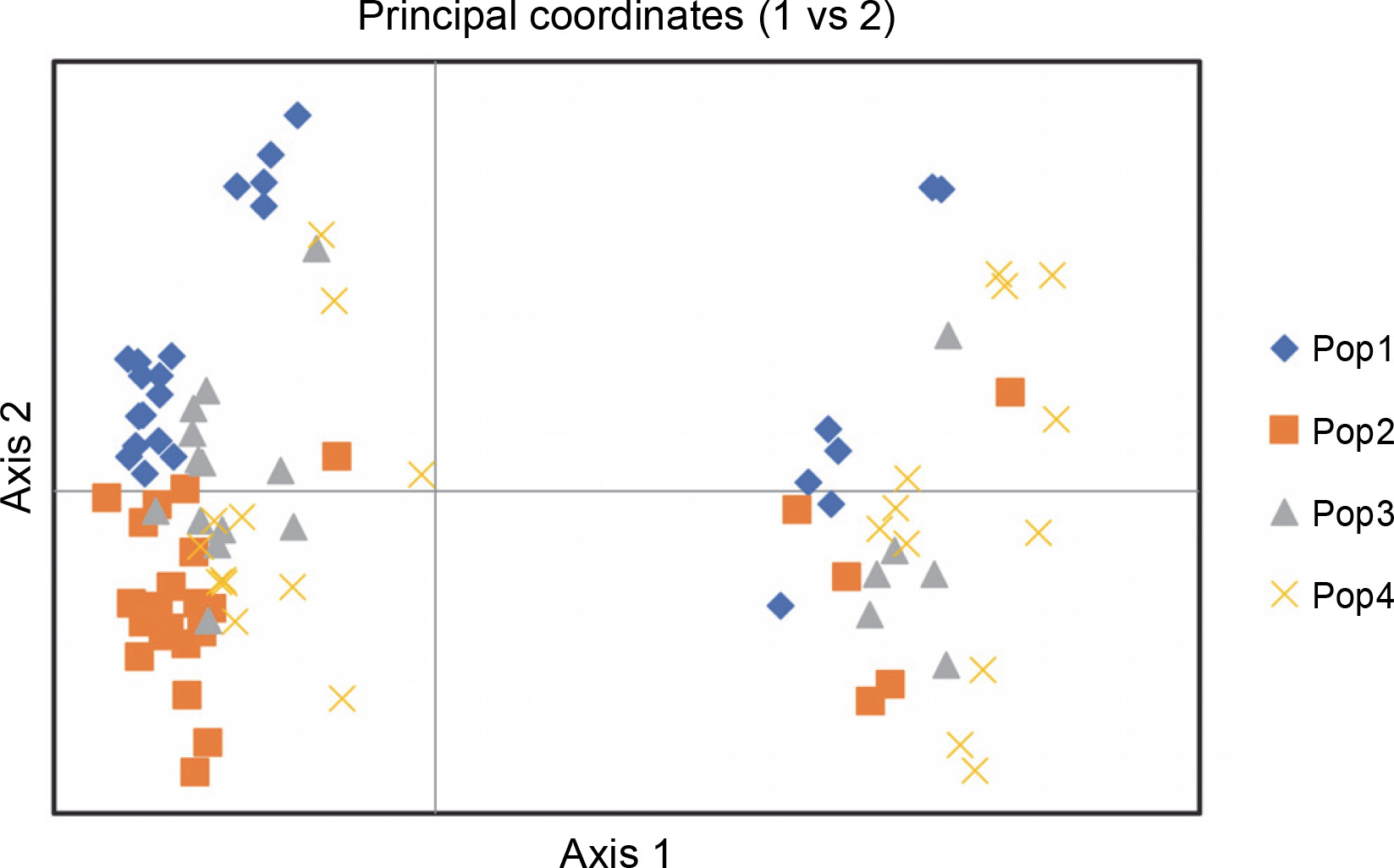
Figure 7 exhibits the analysis of molecular variance (AMOVA). The variation among the four abaca subpopulations was 12%, while 88% allelic differentiation was observed within the population (Table 3). This result was different from Yllano et al. (2020) AMOVA results; nonetheless, both studies recorded low among-population molecular variation and high allelic distribution within populations. This shows that the individuals within the population have higher allelic variability than among populations. The high within-population differentiation may indicate a recent divergence of the abaca accession from their common ancestor. The three-axis generated by PCoA explains 24.63% (Table 4) of the cumulative variation in the abaca germplasm collection. The subpopulations were labeled with different shapes and colors to distinguish them from one another. Members of subpopulations 1–3, except for some data points, were together with their respective populations, while the accessions in subpopulation 4 were scattered all over the PCoA map (Fig. 8).
Table 3
The analysis of variance among and within subpopulations of abaca (Musa textilis Nee)
| Source | df | SS | MS | Est. Var. | % |
|---|---|---|---|---|---|
| Among Pops | 3 | 712.835 | 237.612 | 7.788 | 12 |
| Within Pops | 89 | 5094.401 | 57.240 | 57.240 | 88 |
| Total | 92 | 5807.237 | 65.028 | 100 |
Table 4
The principal coordinate analysis of abaca accessions (Musa textilis Nee)
| Axis | 1 | 2 | 3 |
|---|---|---|---|
| % | 12.09 | 7.24 | 5.30 |
| Cum % | 12.09 | 19.33 | 24.63 |
Colinearity of the UNJ tree and model-based population structure
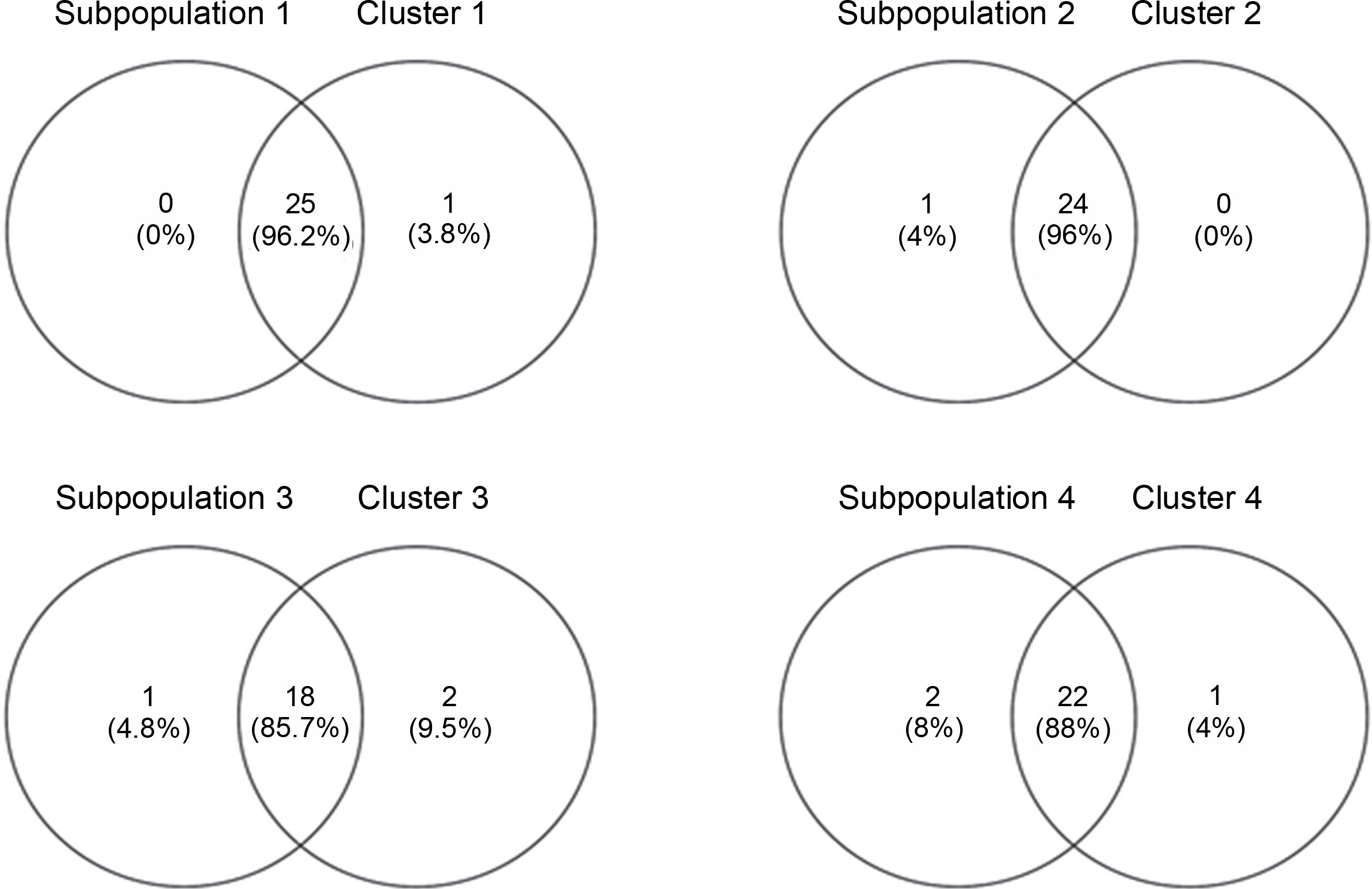
Venny 2.1.0 was used to determine the similarity between the neighbor-joining tree and the subpopulations generated by DARwin and Structure software, respectively (Fig. 9). The percent similarity of each subpopulation with their respective clusters ranged from 85.7 to 96.2%, averaging 91% accessions shared between the populations built by the two software. This shows high corroboration among the generated groupings. Sarabianon was found exclusive to cluster 1 of the UNJ tree but grouped to subpopulation 2 by the Structure software. Populations 3 and 4 and clusters 3 and 4 differed by three accessions: namely, Inosa_b, Lunhan_a, and Putian_a. The high percentage of similarity between the clustering systems exhibits a high accuracy of the developed polymorphic markers.
Cross-transferability to other Musa species
The 28 newly developed genomic SSR primers were also tested for cross-transferability to other Musa species (Fig. 10). The groupings generated from this genetic analysis agree with the previous UNJ tree, except that an additional cluster was formed. The members of the fifth cluster exhibit some morphological characteristics that were a mixture of the botanical descriptions for abaca and banana. In Figure 11, the underside of the leaf blade of the fifth cluster members was powdery and their leaf shape was similar to Pacol (M. balbisiana Colla), however, the distinct red or green line was only found on the underside of the abaca leaf blade was also observed in the fifth cluster’s accessions. Pacol is a well-known wild M. balbisiana Colla accession that showed resistance to the bunchy top virus, it exhibits a wider leaf blade with a powdery underside and overlapping fruit bracts. The markers designed in this study align with all 11 chromosomes of M. balbisiana Colla which is the reason for Pacol grouping with cluster 1. However, there is an obvious difference in the branching and edge length of Pacol to the rest of the accessions in the said cluster indicating genetic differences with the abaca accessions. The result of this transferability shows the specificity of the 28 polymorphic markers to the abaca genome and their capacity to delineate other Musa species. The construction of this tree is supported by the fit criterion of the cophenetic correlation of 91%.
Fig. 10
Unweighted neighbor-joining tree was generated for the 99 Musa collection, to test the cross-transferability of the newly developed molecular markers with other Musa
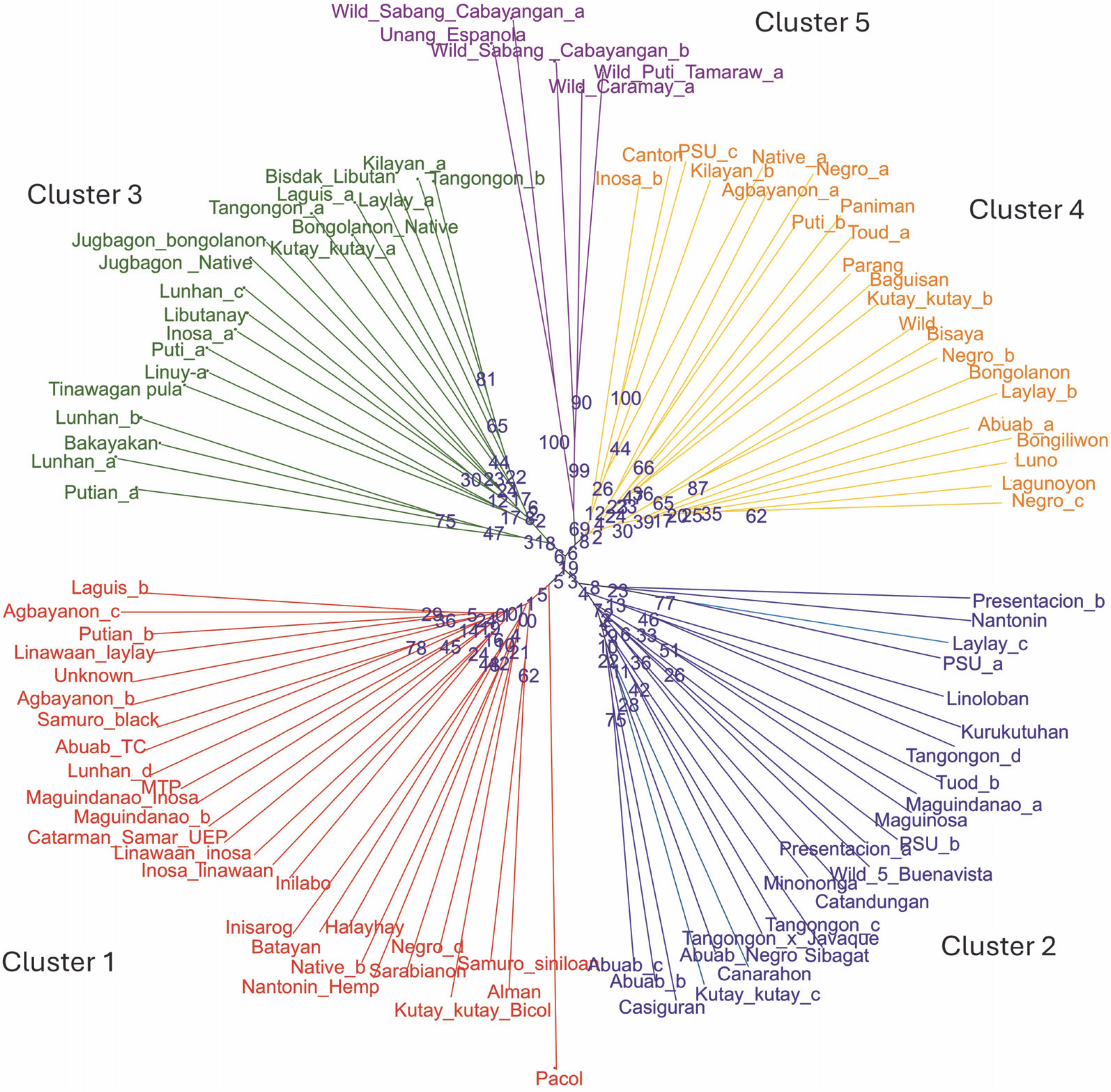
Fig. 11
Member of the fifth cluster from the UNJ tree; (A) powdery leaf blade underside of the members of the fifth cluster (Caramay, Sabang, Tamaraw) is similar to Pacol compared with the glossy underside of the Inosa and Baguisan leaf blades, (B) red or green line found on the right side of the abaca leaf blade was a shared character by the fifth cluster with the abuab

Discussion
Our study is the first report on the efficiency of genome-wide molecular markers based on the whole genome assembly of Abaca var. Abuab. The goal of this study is to develop accurate, inexpensive, and robust primers that can be used for diversity analysis, variety verification, candidate gene association mapping, and hybrid. Our results add to the repository of comprehensive reports on the genetic variability of the abaca collection using SSR markers. The discriminating power of genomic SSRs has been shown in complex genomes like bread wheat (Ahmed et al., 2020) and banana (Biswas et al., 2020), as well as gene mapping for diseases such as stripe rust in wheat (Zhou et al., 2024), indicating the robustness of these markers for assessing genetic variation. This molecular marker system is not only used in the determination and conservation of true genetic resources but also plant breeding. The marker RM16089 was linked to the late-maturing gene Hd16 in rice (Tomita et al., 2022). The BNL252, NAU3424, NAU3324, and CGR5202 SSR markers were highly associated with fiber quality traits of the cotton variety G. barbadense (Ma et al., 2017). Twenty-one SSR markers were found associated with different agronomic traits of maize, such as kernel weight, plant architecture, ear length, and thickness. These studies prove that SSR markers are useful in crop improvement activities in maize (Park et al., 2015).
The identified 50 genomic molecular markers represent scaffolds that aligned to nine of the eleven chromosomes of M. balbisiana Colla indicating their genome-wide distribution in the abaca genome. The polymorphism information content (PIC) value of 0 indicates band monomorphism, while values closer to 1 mean high polymorphism (Hildebrand, 1992). The PIC values of markers are further categorized as highly informative (≥ 0.5), moderately informative (0.50–0.25), or least informative (≤ 0.25) (Botstein et al., 1980). A total of 28 markers out of the newly developed 50 primers showed high polymorphism, ranging from 0.49 (> MK42523) to 0.91 (> MK2915). The polymorphic information content in this study averages 0.78 (> 0.5), showing high allelic diversity among the individual abaca accessions. This average value was also higher than the 0.61 and 0.56 PIC scores obtained from the studies of Boguero et al. (2016) and Yllano et al. (2020), respectively. They both worked on the diversity of abaca however, they used markers based on banana and other genera that have low specificity for abaca resulting in the generation of many clusters. The differences in the genetic composition and number of samples used affect the computed PIC values (Biswas et al., 2020). The 28 highly polymorphic abacabased markers in this study are additional molecular markers to the six banana-based primers previously used on abaca. A total of 14 SSR markers could differentiate and group Ethiopian bananas into three clusters. The markers used show a high average PIC value of 0.82 (Workneh et al., 2022). Similarly, 14 polymorphic primers were able to genotype Musa balbisiana Colla cultivars generating three clusters (Doloiras et al., 2018). The 12 polymorphic SSR primers were also used to determine the clone identity of the banana. Some of these molecular markers generated unique fingerprints for Ardhapuri banana cultivars (Hinge et al., 2022). This showed that even at low numbers, our abaca genome-specific SSR markers are capable of distinguishing individuals and closely related species. Prioritizing only the unique accessions in the germplasm can help in the conservation and proper utilization of true abaca-registered and traditional varieties, especially in germplasm preservation and abaca breeding.
The average genetic diversity computed was 0.428, lower than the observed heterozygosity obtained by Yllano et al. (2020) and Boguero et al. (2016) at 0.52 and 0.92, respectively. This indicates that our collection has moderate heterogeneity. Our results are supported by the fact that the asexual propagation of abaca resulted in its narrow genetic base (Purwati et al., 2018). The mean Fstp value of 0.0815 computed by the Hierfstat package in R indicates moderate diversity between subpopulations. The Fst value shows the allele frequency distribution among populations. The Fst value > 0.25 indicates high genetic differentiation suggesting the accessions came from different species while closer to 0 indicates little genetic differentiation. The intermediate or moderate differentiation lies between 0.05 and 0.15 Fst values (Li et al., 2014; Luo et al., 2019). The mean value of alpha obtained from population analysis was α = 0.0735. The relatively small alpha values mean that a few members of the population were admixed, and the accessions originated from one ancestor. The alpha value approaching zero indicates that the accessions are from separate populations, while if it is greater than 1, it means that the members are highly admixed and originated from multiple sources. This agrees with the computed population heterozygosity of 0.428 and the AMOVA results, where greater within population variation (88%) was found.
Boguero et al. (2016) looked at the association of six SSR primers with bunchy-top disease and generated 10 groups using cluster analysis, while Yllano et al. (2020) used banana-based microsatellite markers that produced 9 clusters in the neighbor-joining tree. The high allelic distribution of SSR markers tends to produce increased genetic variation even among closely related species (Aiello et al., 2020) resulting in more clusters. The nature of populations and molecular markers also cause varying population structures (Zhu et al., 2016). The specificity of the 28 genomic markers used for abaca accessions in this study resulted in only four inferred populations. Two different software programs (DARwin and STRUCTURE v. 2.3.4) generated clusters and populations that were 91% similar according to the Venn diagram analysis. This percent collinearity is considered high because a percent similarity of 55% between the clusters and population exhibited high support in a genetic study of rice germplasm (Singh et al., 2016). The four subpopulations identified by DARwin showed that some samples bearing similar names grouped with varying clusters. The population structure analysis, on the other hand, revealed the allelic distribution per accession and revealed that the accession that clustered differently by DARwin possessed allele distribution bordering two subpopulations. The inferred clusters also show that the accessions with inverted names are identical varieties. This shows that the newly developed genome-wide SSR markers specificity of markers dedicated to genetic diversity analysis, variety identification, and association mapping for abaca. These newly developed polymorphic markers will assist the breeders in planning hybridization activities and selecting the true abaca varieties that can be used in crop improvement given that the abaca population has moderate genetic diversity.
The cross-transferability of markers based on the genomes of other species has been done in abaca (Yllano et al., 2020), asparagus (Geetha and Siril, 2022), and fennel (Aiello et al., 2020). For the fennel, only 23% of carrot SSR markers were transferable; therefore, they concluded that the transferability of primers across genera is challenging (Aiello et al., 2020). The 28 markers used in this study were able to identify other Musa species that share physical similarities with abaca and place them in an additional cluster in the UNJ tree. In addition, the association of Pacol with Cluster 1 shows that abaca and M. balbisiana Colla share genetic similarities but are not the same, for they differ in branch length and placement in Cluster 1. This shows that the markers can delineate abaca from their close relative Musa species. Oftentimes, farmers label the same variety with different names (Halos, 2008). This is perhaps the case with some of the abaca cultivars in this study. The accessions were given different names by farmers but are the same, and vice versa. This is due to the confusing morphology that the abaca shares with one another and other Musa species. The 28 genomic markers were able to fingerprint the members of the abaca germplasm collection.
The percent of molecular variance found in the collection was 12% among populations and 88% within populations. These results corroborate with Yllano et al. (2020), who generated 5% among population variance and 95% within populations. The low percent variation among the population was also observed in rice (Singh et al., 2016) and grain amaranth (Vats, 2023). Some of the grouping established in this study corroborates with the clusters generated by SNP data of Barbosa et al. (2023) where Tangongon, Puti, and Kutay_kutay_a are grouped in the same cluster (cluster 3). Abuab_a, Luno, and Inosa_b are members of cluster 4. This proves that developed molecular markers can fully characterize the abaca populations. Our primers are hypervariable, widely distributed, and informative tools; hence it became our go-to marker of choice.
Conclusion
The improvement in genotyping and variety identification of abaca eases conventional breeding techniques and maximizes resources for germplasm conservation. The intense selection bias towards elite individuals results in the neglect of the diverse genetic sources available in the field. This study increased specificity in genotyping physically similar Musa collections through the use of polymorphic SSR loci (-78% PIC). Accessions that shared the same names were grouped in clusters using two different diversity analysis tools (DARwin and Structure v2.3.4). Our study is a thorough examination of the extent of the relatedness of abaca and DNA fingerprints using genome-wide molecular markers. The abaca germplasm collection used in this study was collected from ten regions in the Philippines, and many of them shared similar or same names. Using molecular markers, especially these genome-specific markers, saves time in fingerprinting, variety verification, and candidate gene linkage mapping of economically important traits. This study is an in-depth look at the genetic variability among the members of the abaca gene bank.